TXT整理系统:改造novel-plus管理本地小说
前言
收集了大量本地 TXT 小说,希望能像正常小说站一样阅读、检索、分类、下载,于是使用Codex二开了 novel-plus项目,将其改造成一个本地 TXT 小说整理、入库、维护和发布系统。
入库流程
1 | 扫描 TXT |
扫描 TXT
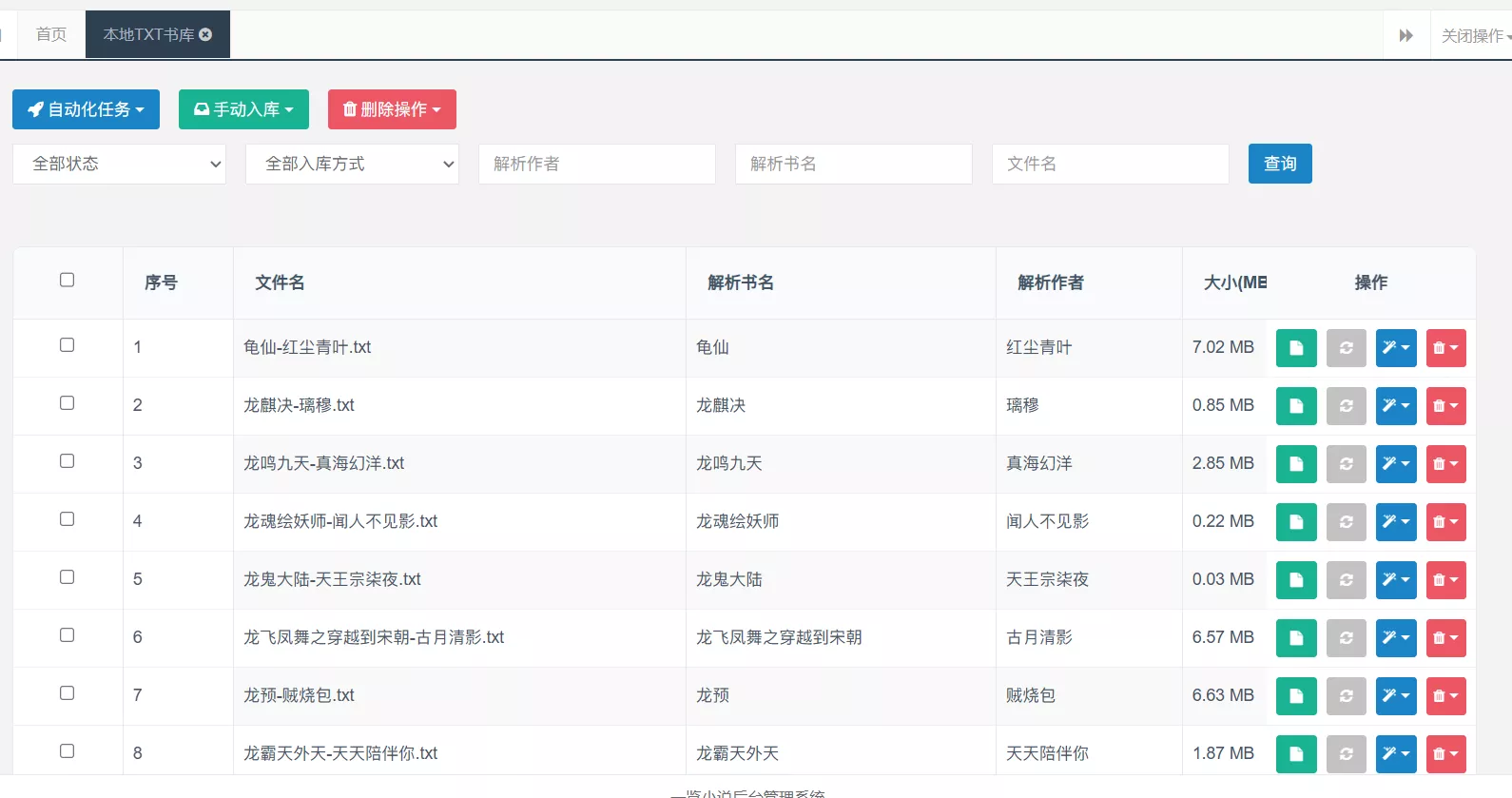
后台指定一个本地目录后,系统会递归扫描里面的 .txt 文件。
扫描阶段只负责发现文件、记录文件路径、文件大小、修改时间和文件 hash。真正能不能入库,还要继续看文件名、正文质量和章节识别结果。
解析文件名
系统目前能识别解析的文件名规则:
1 | 书名-作者.txt |
例如:
1 | 凡人修仙传-忘语.txt |
也支持:
1 | 书名-作者.txt |
文件名解析成功后,系统才能拿到最基础的书名和作者。文件名解析失败的 TXT 不会假装入库成功,而是进入待处理状态。
读取编码并统一文本
TXT 来源复杂,常见编码包括 UTF-8、GBK、GB18030 等。
系统会先读取原始 TXT,并尝试识别编码,把内容转成 Java 内部统一处理的文本。这样后面的清洗正文、章节识别、生成受管 TXT,才不会直接被乱码拖垮。
清洗正文
读取文本后,会先做正文清洗,再识别章节。
清洗主要处理这些问题:
- HTML 换行和简单 HTML 标签。
- 广告行、来源站提示、无意义尾巴。
- 多余空行。
- 行尾多余空白。
清洗规则做成了规则文件,方便后续补充新的广告特征。
设置有两个规则文件:
1 | novel-admin/src/main/resources/local-txt-drop-line-keywords.txt |
local-txt-drop-line-keywords.txt 用来删除整行。规则是:一行内容归一化后,只要包含其中任一关键词,就整行丢弃。它适合放版权声明、防盗提示、采集站尾巴、跳转提示等。
local-txt-strip-line-fragments.txt 用来删除行内片段。规则是:只删除命中的片段,保留同一行的其他正文。它适合处理插在正文里的短广告、站点口号、防盗提示。
识别章节
为了能正常阅读整本上传的txt小说,需要建立章节索引
理想格式是:
1 | 第一章 初入江湖 |
当前系统使用“顶格短行”识别。只要某一行顶格、够短、不是网址、没有命中黑名单,就会被识别成章节标题。
要求:章节标题最好顶格单独一行,正文里不要堆大量顶格短句,否则可能误切章节。
生成受管 TXT
扫描入库后,系统会把原始 TXT 清洗成 UTF-8 受管 TXT,保存到类似目录:
1 | data/books/local_txt/{bookId}/书名-作者.txt |
受管 TXT 是系统后续阅读、替换重建、备份和网盘发布的基础文件。导入后的正文不再依赖最初扫描目录里的原始 TXT。
建立章节索引
章节识别成功后,系统会把每一章的标题、顺序、字数、正文起止位置写入数据库的章节索引。
前台阅读时,不是重新从头扫描整本 TXT,而是根据章节索引定位受管 TXT 里的对应片段,所以章节索引和受管 TXT 必须保持一致。
提取元数据
TXT 本身通常只有正文,没有封面、简介、分类、完结状态。
为了解决这个问题,做了元数据提取流程。
它分两层:
1 | 规则源匹配 |
提取流程:
- 规则源能命中,就优先使用规则源。
- 规则源分类缺失或简介太差,再让 AI 补分类、补简介。
- 规则源失败,再切 AI 兜底。
- AI 返回的简介如果明显乱码、太短、默认化,会被过滤。
- AI 返回的分类必须能映射到系统分类,否则不会盲目写入。
分类整理磁盘
元数据获取到分类后,会把入库的txt文件整理到对应的分类。
元数据完善后,再整理成:
1 | data/books/local_txt/男频/玄幻奇幻/{bookId}/书名-作者.txt |
数据库里的 local_txt_book.storage_rel_path 记录真实相对路径。
这意味着不能随便在 Linux 上手动移动文件。文件移动和数据库路径更新必须一起完成,否则前台阅读就可能找不到正文。
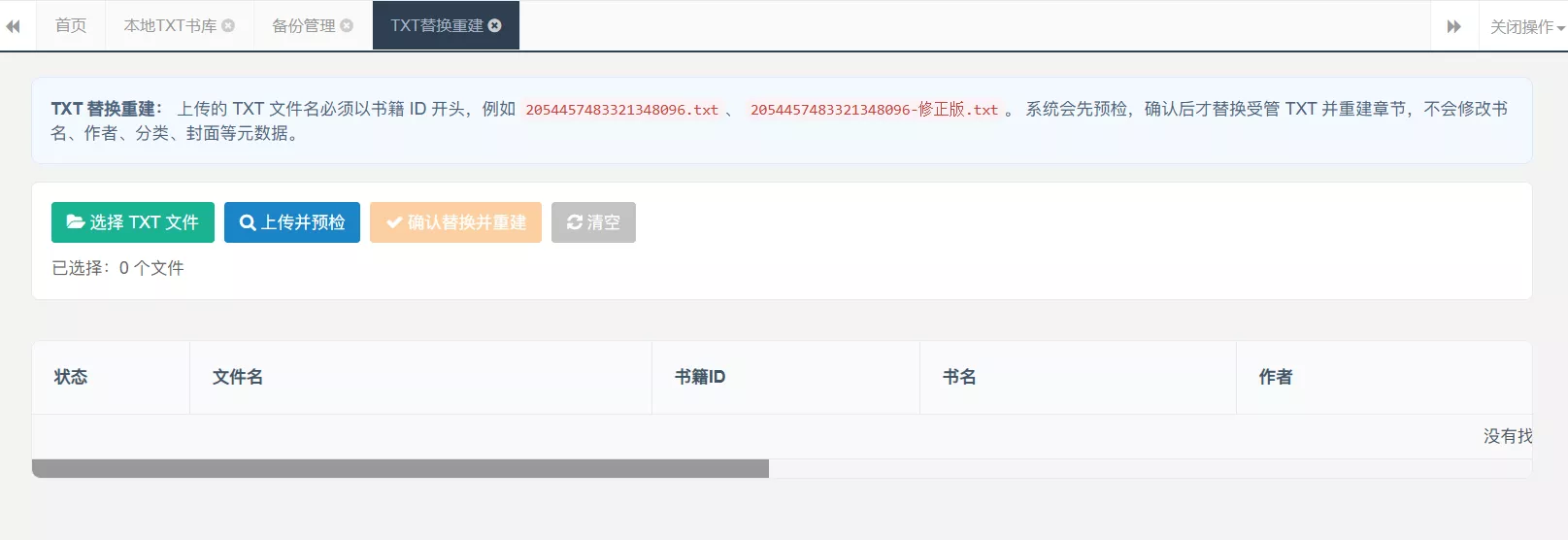
TXT 替换重建
入库后仍然会遇到一种情况:前台阅读时才发现某本 TXT 是坏的(比如章节索引有问题,txt内容问题等),需要重新上传干净规范的txt文件。
- 从前台书籍链接拿到 bookId。
- 把新 TXT 命名为
bookId-修正版.txt。 - 后台上传。
- 系统预检。
- 确认替换并重建章节。
例如:
1 | 2054457483321348096-修正版.txt |
系统会根据文件名前缀找到书籍,自动定位受管 TXT 路径,然后替换正文并重建章节索引。
这个过程不会修改书名、作者、分类、封面、简介。
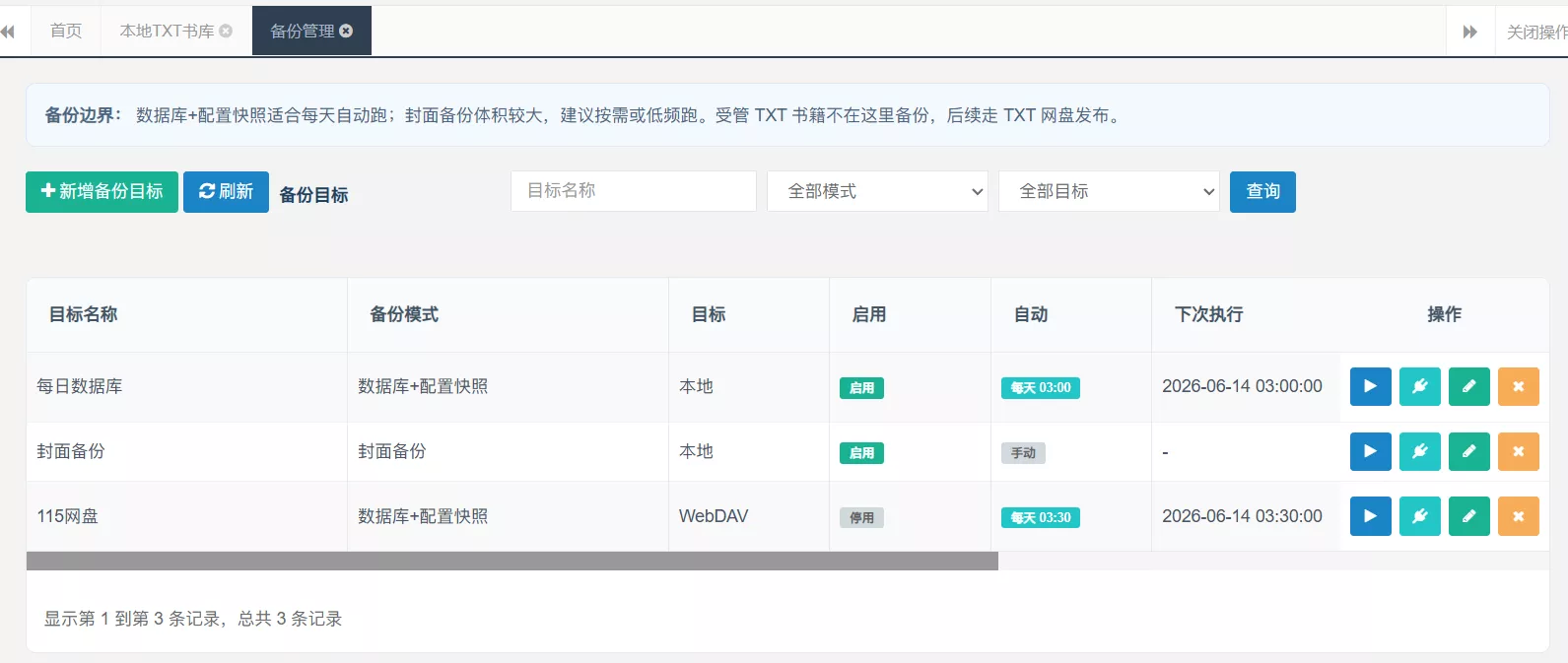
数据备份
当前备份分两类:
1 | 数据库+配置快照 |
数据库+配置快照包含:
1 | database.sql.gz |
备份目标分为:
1 | 本地 |
备份方式是:
1 | 本地目标每天生成一次备份 |
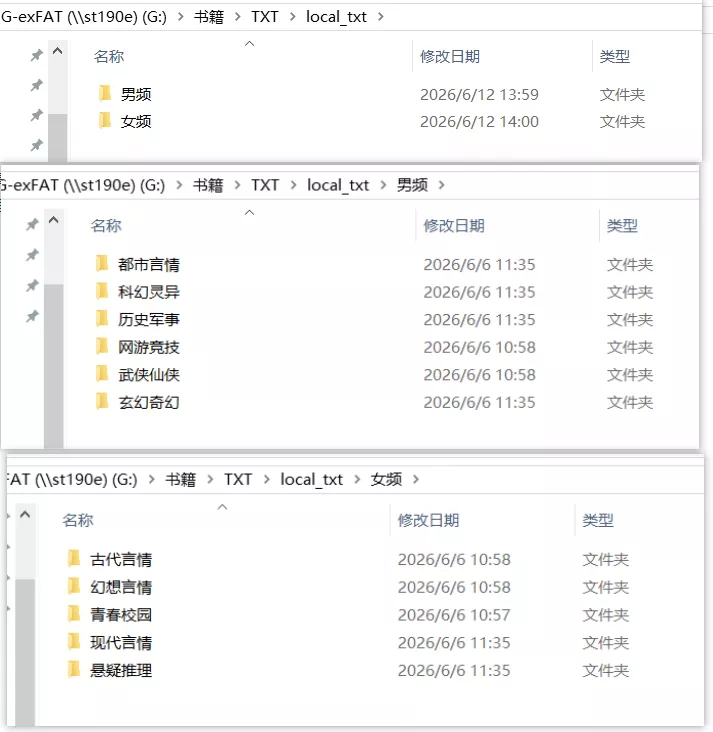
最终效果
本地磁盘的小说目录层级和站点的小说分类完全同步